
フィーチャーフラグマネジメント・A/Bテストプラットフォーム「Bucketeer」チームにてバックエンドエンジニアをしている小野です。
最近、Bucketeer では Feature Flag Dependencies という機能がリリースされました。この機能の内部実装にはトポロジカルソートが用いられており、本稿では開発者である筆者がアルゴリズムの選定理由を含めた経緯についてお話ししていきます。
想定読者
本稿では、以下のような読者を想定しておりフィーチャーフラグの運用方法についてのお話しはしません。
- Bucketeer の内部実装の仕組みについて知りたい
- トポロジカルソートについて知りたい
- アルゴリズムの選定理由について知りたい
Bucketeer について
先述したように、Bucketeer ではフィーチャーフラグをまとめて管理できます。以下に例を示します。
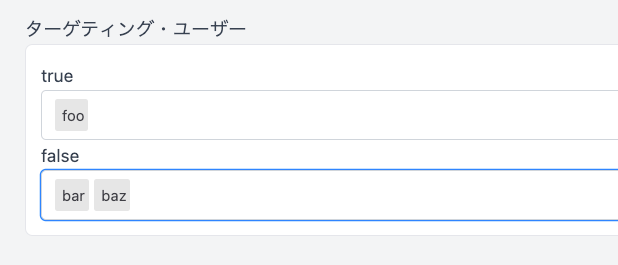
この設定の場合、ユーザーの ID が "foo" の時は true を返し、"bar"、"baz" の時は false を返します。必要に応じて GUI で簡単にフラグの値を変えることができます。
Feature Flag Dependencies とは
Feature Flag Dependencies は対象となるフィーチャーフラグそのものを評価対象とできる機能です。
例えば、フィーチャーフラグAを評価した際に返ってきた値が true である時のみフィーチャーフラグBを評価するというものです。もし、フィーチャーフラグAの値が false だった(期待したものと異なる)場合はフィーチャーフラグBを評価せず、デフォルトの値を返すような仕組みになっています。
少しの違いはあるものの、代表的なフィーチャーフラグマネジメントサービスには以下のようにサポートされている機能になっています。
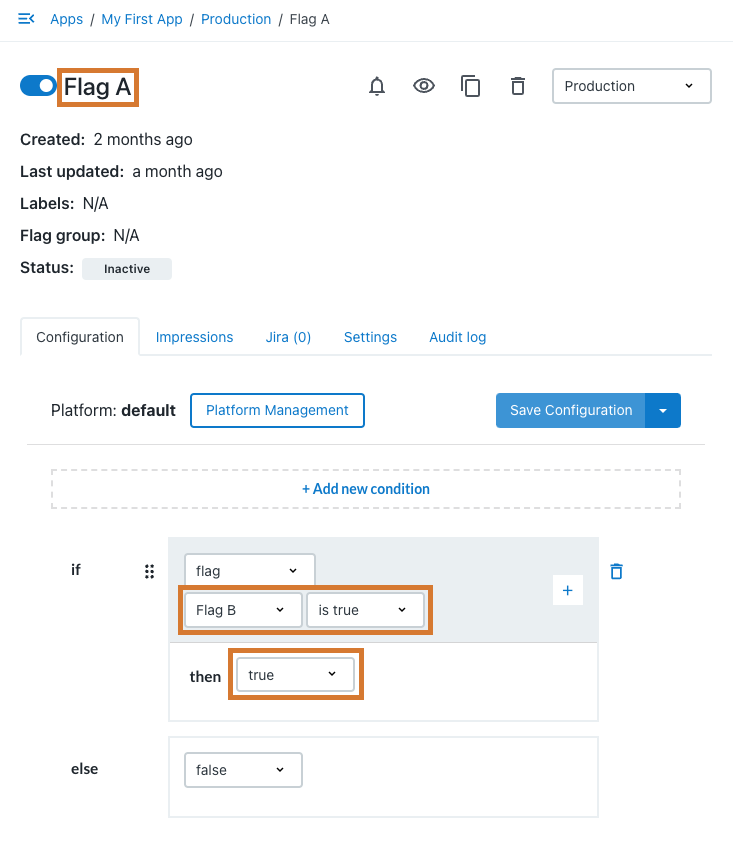
実装するにあたっての要件
要件は以下のようになっています。
- 前提条件となっているフィーチャーフラグは全て論理演算子における AND として評価する
- フィーチャーフラグ間でサイクルがあってはいけない
- 前提条件として設定できるフィーチャーフラグの数に制限は設けない
要件をもとに、フィーチャーフラグを頂点としてデータ構造を考えてみると、各辺に向きがあり、閉路を持たないグラフであることが分かります。このようなグラフは有向非巡回グラフ(以下、DAG)と呼ばれ、タスク間での優先順位などを表現する際に用いられるものなっています。
実装方針
データ構造を踏まえて、以下の実装方針に決めました。
- トポロジカルソートを行い、先に評価しなければならないフィーチャーフラグから先頭に並んでいる配列を作る
- 配列を用いて順に評価していく
トポロジカルソートとは
トポロジカルソートは DAG の各頂点を辺の向きに合わせてソートするアルゴリズムです。以下のようなグラフがあったとします。
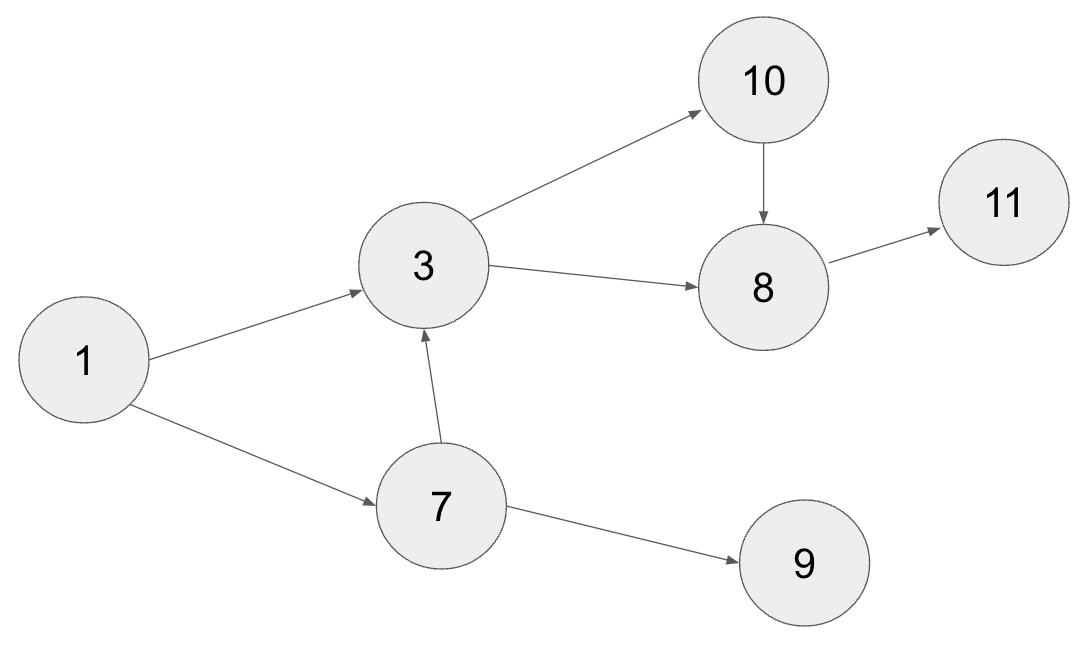
辺の向きに合わせてソートすると、以下のようになります。
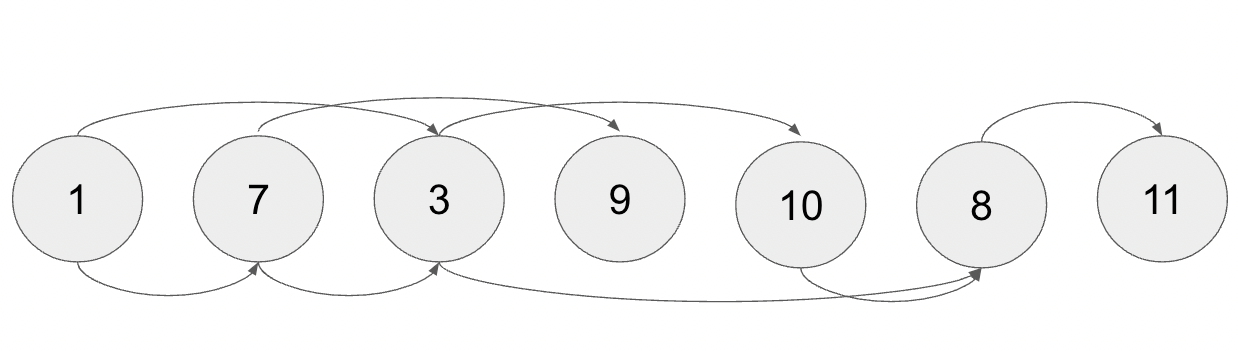
ソート順は一意とは限らず、複数あることもあります。
今回実装したトポロジカルソートについての解説
それでは、実際の実装について紹介をしていきます。トポロジカルソートとは辺の向きに合わせてソートするものだと先ほど述べました。
しかし、今回のケースにおいては、前提条件になっているフィーチャーフラグから評価をする必要があるので、先ほどのグラフを用いると以下のようにソートする必要があります。
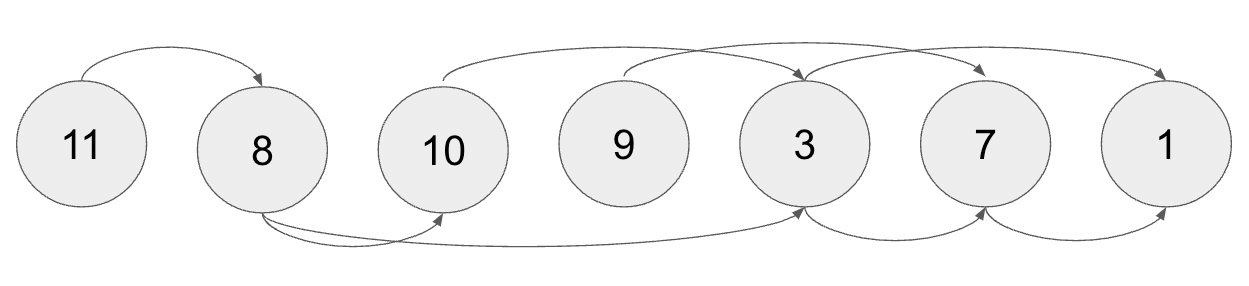
注意したいのは、先述したトポロジカルソートとは逆向きにソートしている点です。辺の向きに合わせてソートすると先ほど述べましたが、今回は辺の向きと逆順でソートするようにしています。
実際に Bucketeer に書かれているコードを引用します。
func TopologicalSort(features []*featureproto.Feature) ([]*featureproto.Feature, error) {
marks := map[string]Mark{}
mapFeatures := map[string]*featureproto.Feature{}
for _, f := range features {
marks[f.Id] = unvisited
mapFeatures[f.Id] = f
}
var sortedFeatures []*featureproto.Feature
var sort func(f *featureproto.Feature) error
sort = func(f *featureproto.Feature) error {
if marks[f.Id] == permanently {
return nil
}
if marks[f.Id] == temporary {
return ErrCycleExists
}
marks[f.Id] = temporary
for _, p := range f.Prerequisites {
pf, ok := mapFeatures[p.FeatureId]
if !ok {
return errFeatureNotFound
}
if err := sort(pf); err != nil {
return err
}
}
marks[f.Id] = permanently
sortedFeatures = append(sortedFeatures, f)
return nil
}
for _, f := range features {
if marks[f.Id] != unvisited {
continue
}
if err := sort(f); err != nil {
return nil, err
}
}
return sortedFeatures, nil
}
https://github.com/bucketeer-io/bucketeer/blob/v0.2.0/pkg/feature/domain/evaluation.go#L100-L139 より引用
再帰関数で深さ優先探索的に頂点を辿っていき、関数を抜けた順で配列(`sortedFeatures`という変数)に挿入をしています。
関数を抜けた順で挿入をすることで、前提条件となっているフィーチャーフラグ(矢印が向いている先の頂点)から順に挿入がされます。
同時に、フィーチャーフラグ間で閉路がないか確認していて、閉路が存在する場合はエラーを返すようにしています。
閉路については、訪れた頂点の状態を確認することで検出しています。ここでいう状態とは各頂点が探索対象となってから配列に挿入されるまでのことを示しています。各頂点はいずれも以下のように状態を遷移していきます。
- その頂点にまだ訪れていない(以下、unvisited と呼ぶ)
- その頂点に訪れている状態。前提条件となる頂点を挿入している途中でまだ配列へ挿入はされていない(以下、temporary と呼ぶ)
- その頂点は既に挿入されていて、再び訪れることはない(以下、permanently と呼ぶ)
このうち、前提条件となる頂点に2の状態のものがあれば、閉路が存在するということが出来ます。
例えば、以下のように閉路を持つグラフをソートしてみます。中に書かれている数字はフィーチャーフラグの ID だと思ってください。特定のフィーチャーフラグを指す時、「フィーチャーフラグ<ID>」と呼ぶことにします(5と書かれているフィーチャーフラグはフィーチャーフラグ5となる)。
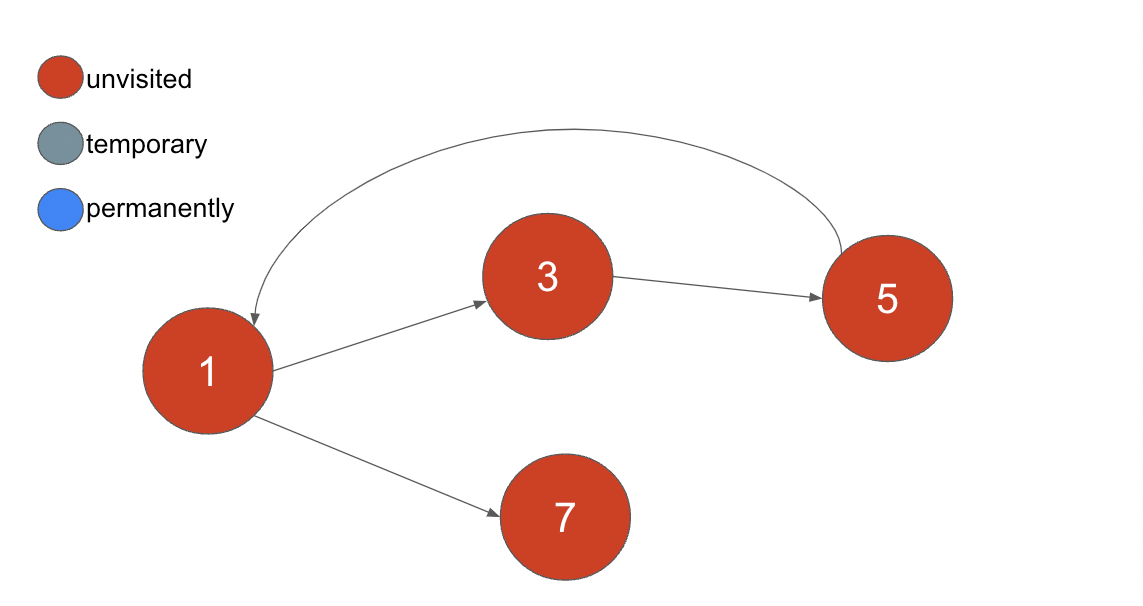
まずは、フィーチャーフラグ1を訪れます。1には前提条件となるフィーチャーフラグが存在しているのでステータスを temporary とします。
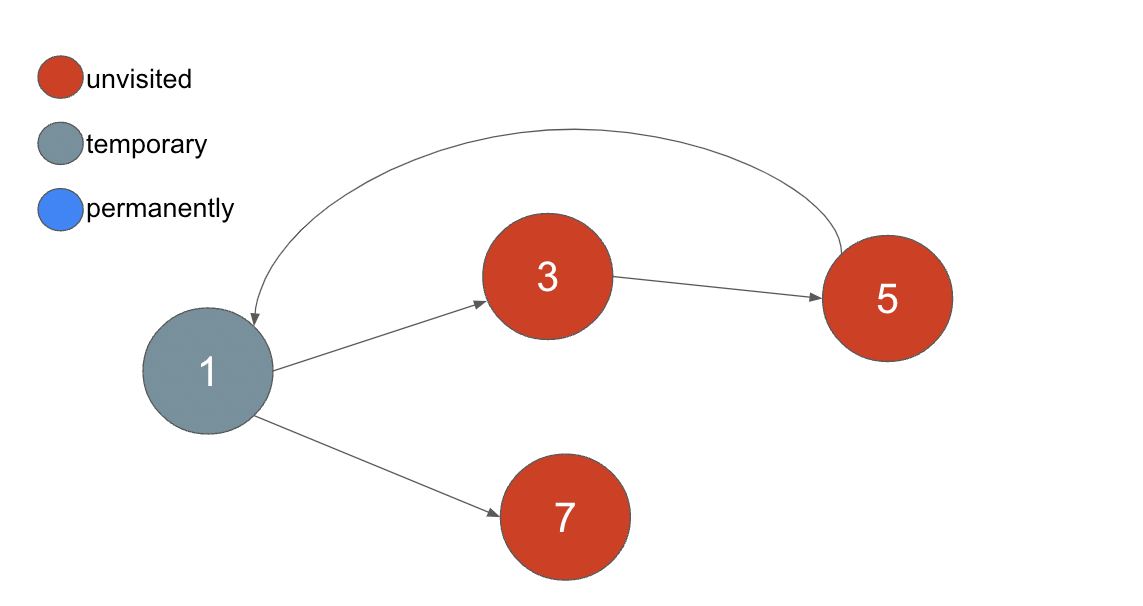
次にフィーチャーフラグ7を訪れます。7には前提条件となるフィーチャーフラグが存在しない為、配列に挿入しステータスを permanently とします。
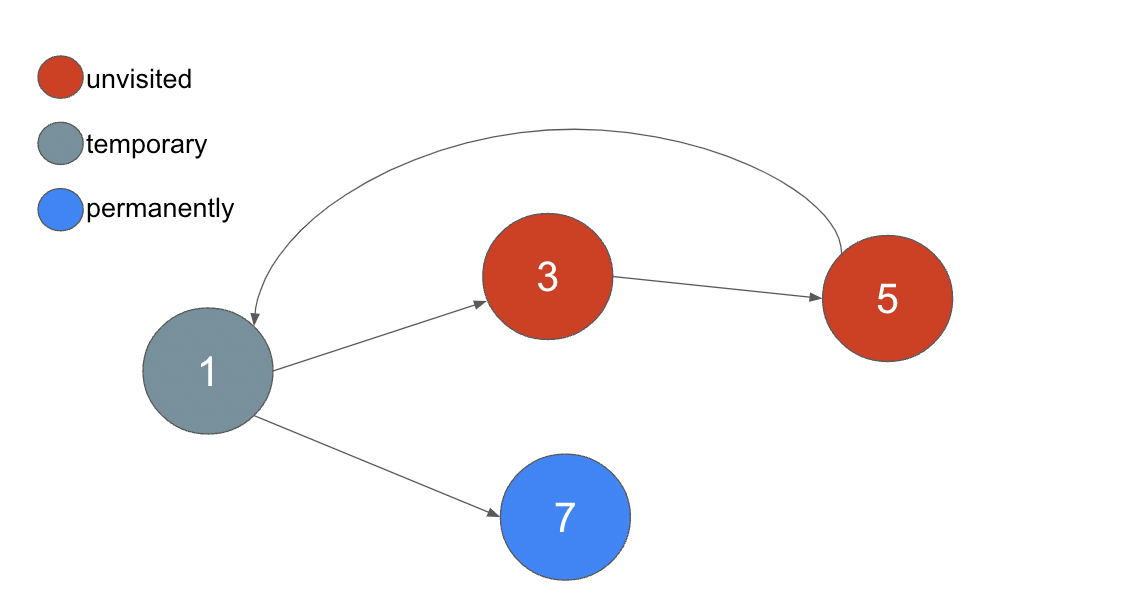
次にフィーチャーフラグ3を訪れます。3には前提条件となるフィーチャーフラグが存在する為、ステータスを temporary とします。
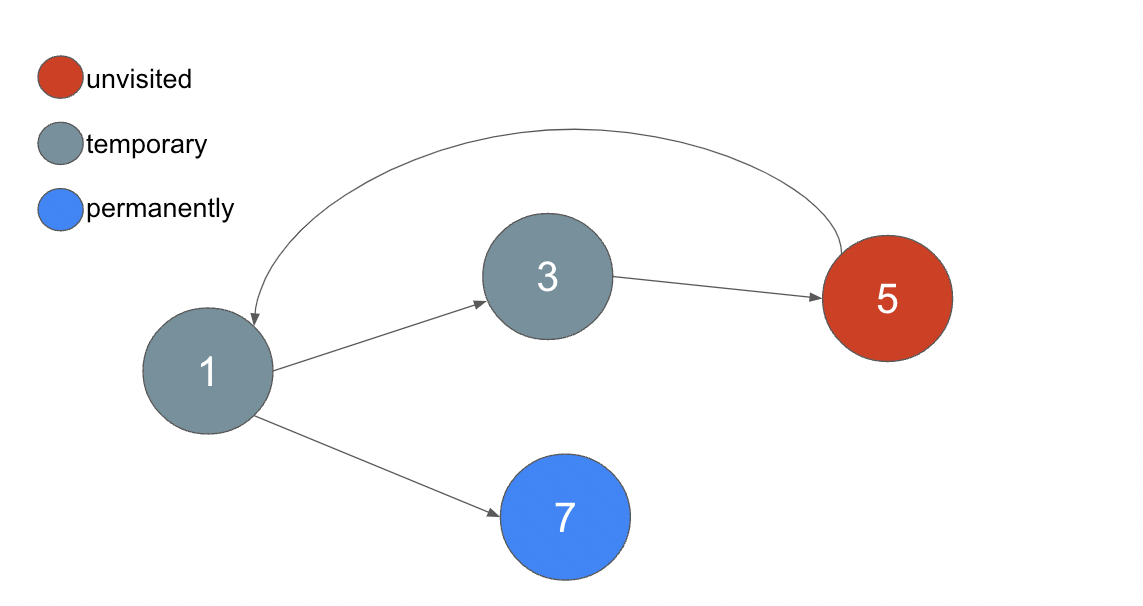
次にフィーチャーフラグ5を訪れます。5には前提条件となるフィーチャーフラグが存在する為、ステータスを temporary とします。
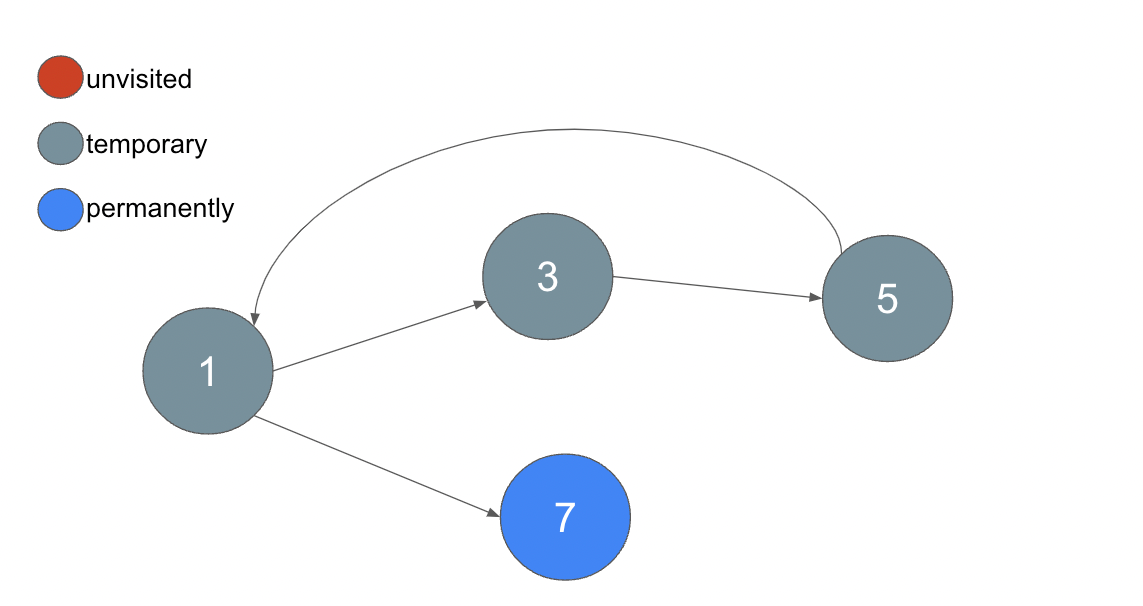
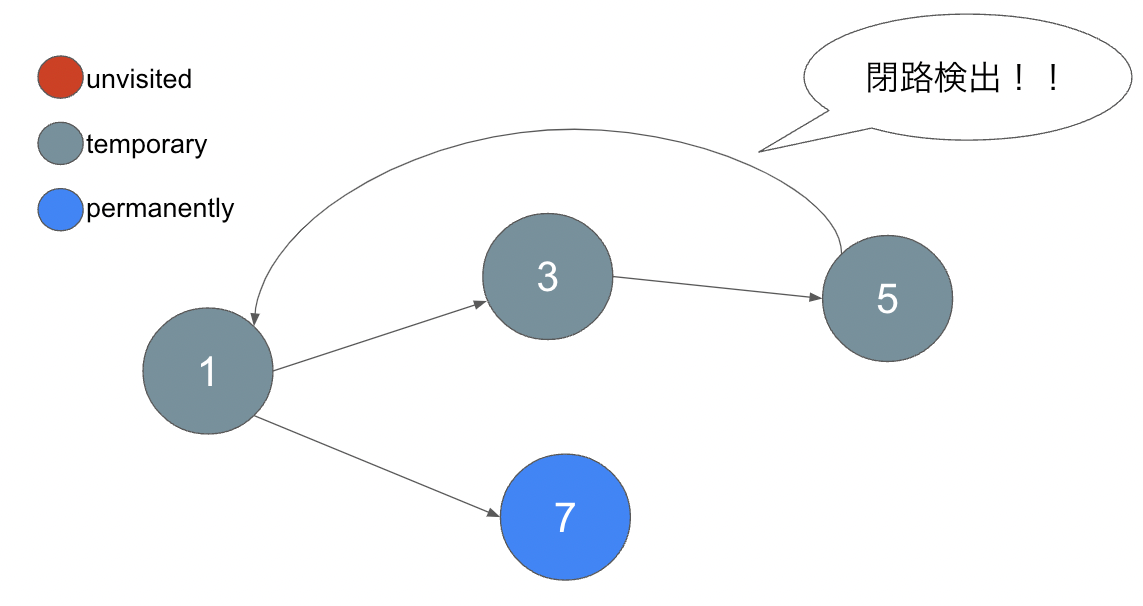
フィーチャーフラグ1を訪れますが、ここでステータスを確認すると temporary になっています。よって、閉路を検出することができました。
最後に
今回、実装する上で一番難しかった部分は要件からデータ構造が DAG であると見抜くところでした。プロジェクト固有のものとして考えてしまいがちですが、コンピューターサイエンスにおける普遍的なデータ構造に置き換えて考えることができたのは面白い経験でした。
謝辞
今回の機能を実装するにあたって、沖本さん、小塚さんには多くの有用な意見をいただきました。ありがとうございました。
引用・参考文献
「問題解決力を鍛える!アルゴリズムとデータ構造」
 Contributors to Wikimedia projects
Contributors to Wikimedia projects
